Pyspark Read From S3
Pyspark Read From S3 - Web how to access s3 from pyspark apr 22, 2019 running pyspark i assume that you have installed pyspak. Now, we can use the spark.read.text () function to read our text file: If you have access to the system that creates these files, the simplest way to approach. Web feb 1, 2021 the objective of this article is to build an understanding of basic read and write operations on amazon. We can finally load in our data from s3 into a spark dataframe, as below. Interface used to load a dataframe from external storage. Web spark read json file from amazon s3. Web and that’s it, we’re done! Pyspark supports various file formats such as csv, json,. Note that our.json file is a.
Web read csv from s3 as spark dataframe using pyspark (spark 2.4) ask question asked 3 years, 10 months ago. Web spark read json file from amazon s3. Web step 1 first, we need to make sure the hadoop aws package is available when we load spark: We can finally load in our data from s3 into a spark dataframe, as below. Web this code snippet provides an example of reading parquet files located in s3 buckets on aws (amazon web services). It’s time to get our.json data! If you have access to the system that creates these files, the simplest way to approach. Note that our.json file is a. Web to read data on s3 to a local pyspark dataframe using temporary security credentials, you need to: Now, we can use the spark.read.text () function to read our text file:
Web if you need to read your files in s3 bucket you need only do few steps: Web step 1 first, we need to make sure the hadoop aws package is available when we load spark: Interface used to load a dataframe from external storage. Note that our.json file is a. Web spark sql provides spark.read.csv (path) to read a csv file from amazon s3, local file system, hdfs, and many other data. It’s time to get our.json data! Read the text file from s3. Web this code snippet provides an example of reading parquet files located in s3 buckets on aws (amazon web services). If you have access to the system that creates these files, the simplest way to approach. Now, we can use the spark.read.text () function to read our text file:

Read files from Google Cloud Storage Bucket using local PySpark and
Web read csv from s3 as spark dataframe using pyspark (spark 2.4) ask question asked 3 years, 10 months ago. Interface used to load a dataframe from external storage. Web spark read json file from amazon s3. Read the text file from s3. Now, we can use the spark.read.text () function to read our text file:

PySpark Create DataFrame with Examples Spark by {Examples}
Web if you need to read your files in s3 bucket you need only do few steps: Web read csv from s3 as spark dataframe using pyspark (spark 2.4) ask question asked 3 years, 10 months ago. Web now that pyspark is set up, you can read the file from s3. Web feb 1, 2021 the objective of this article.

PySpark Read CSV Muliple Options for Reading and Writing Data Frame
Note that our.json file is a. Now, we can use the spark.read.text () function to read our text file: Web now that pyspark is set up, you can read the file from s3. Web this code snippet provides an example of reading parquet files located in s3 buckets on aws (amazon web services). Interface used to load a dataframe from.

Spark SQL Architecture Sql, Spark, Apache spark
It’s time to get our.json data! To read json file from amazon s3 and create a dataframe, you can use either. Web now that pyspark is set up, you can read the file from s3. Read the text file from s3. Read the data from s3 to local pyspark dataframe.

PySpark Read JSON file into DataFrame Cooding Dessign
Now that we understand the benefits of. Web step 1 first, we need to make sure the hadoop aws package is available when we load spark: Web if you need to read your files in s3 bucket you need only do few steps: Web to read data on s3 to a local pyspark dataframe using temporary security credentials, you need.

Array Pyspark? The 15 New Answer
Web spark sql provides spark.read.csv (path) to read a csv file from amazon s3, local file system, hdfs, and many other data. Web step 1 first, we need to make sure the hadoop aws package is available when we load spark: Read the data from s3 to local pyspark dataframe. Web read csv from s3 as spark dataframe using pyspark.
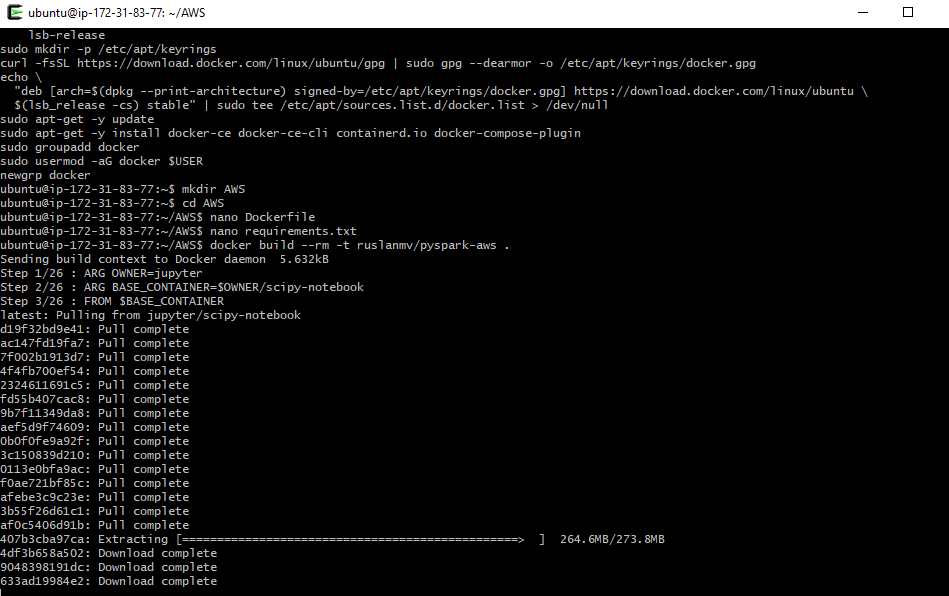
How to read and write files from S3 bucket with PySpark in a Docker
Web now that pyspark is set up, you can read the file from s3. Now that we understand the benefits of. Web if you need to read your files in s3 bucket you need only do few steps: Web to read data on s3 to a local pyspark dataframe using temporary security credentials, you need to: Note that our.json file.
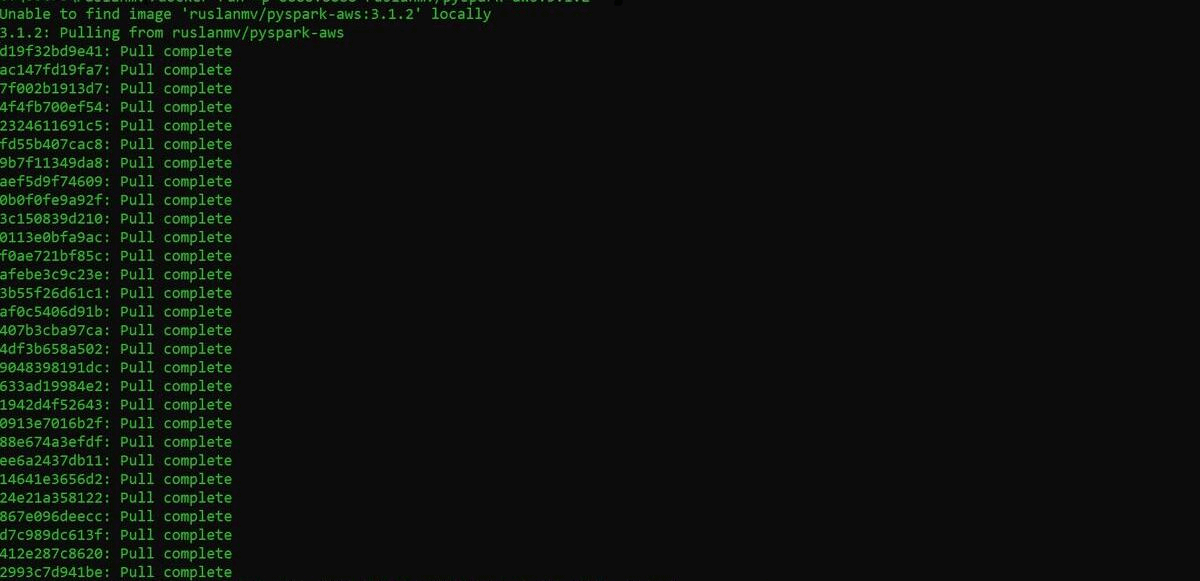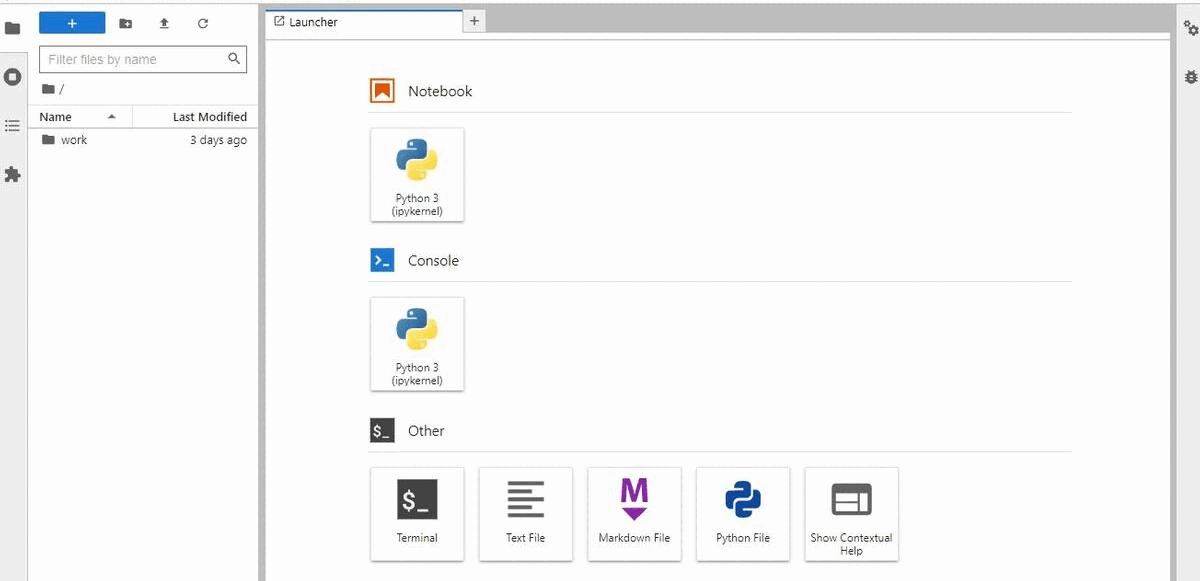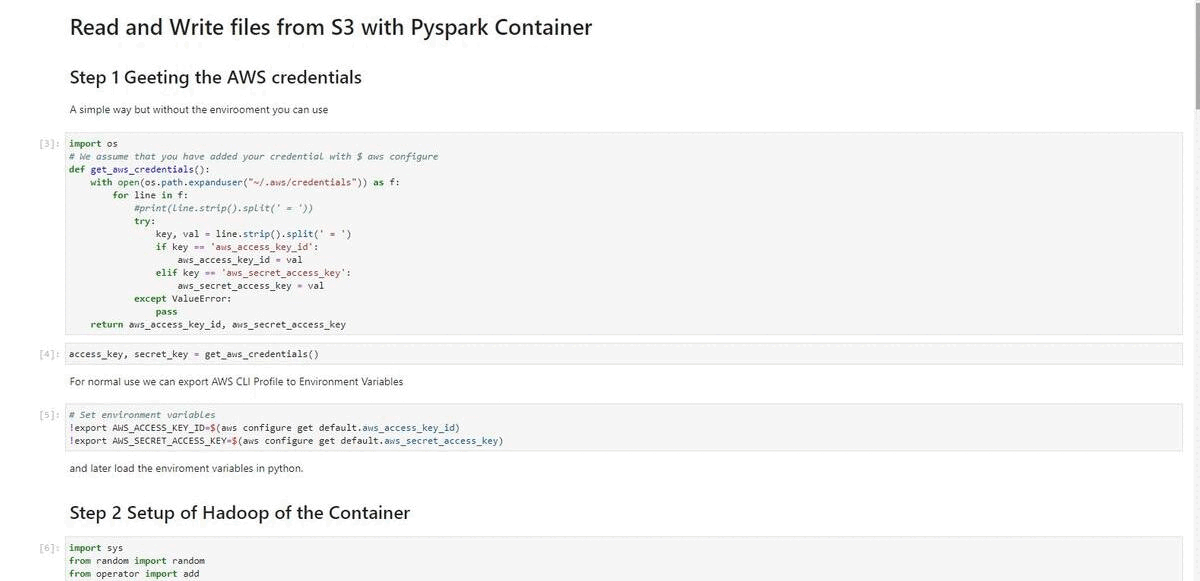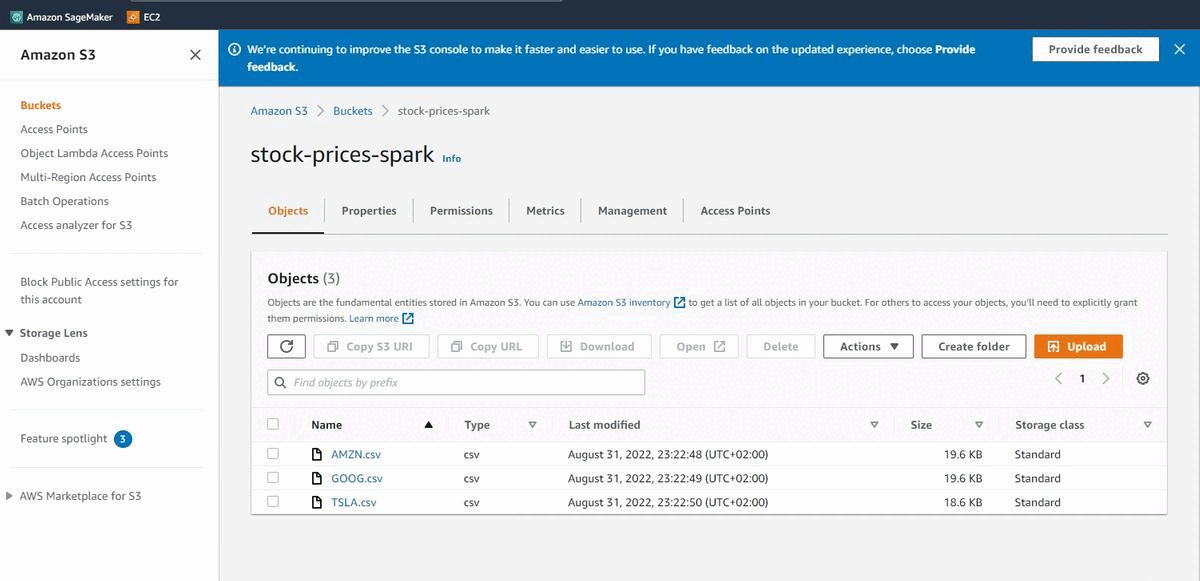
How to read and write files from S3 bucket with PySpark in a Docker
Web to read data on s3 to a local pyspark dataframe using temporary security credentials, you need to: Web and that’s it, we’re done! Interface used to load a dataframe from external storage. Interface used to load a dataframe from external storage. To read json file from amazon s3 and create a dataframe, you can use either.

PySpark Tutorial24 How Spark read and writes the data on AWS S3
Web this code snippet provides an example of reading parquet files located in s3 buckets on aws (amazon web services). Web if you need to read your files in s3 bucket you need only do few steps: Web step 1 first, we need to make sure the hadoop aws package is available when we load spark: Web spark read json.

apache spark PySpark How to read back a Bucketed table written to S3
If you have access to the system that creates these files, the simplest way to approach. Read the data from s3 to local pyspark dataframe. Now, we can use the spark.read.text () function to read our text file: Web spark sql provides spark.read.csv (path) to read a csv file from amazon s3, local file system, hdfs, and many other data..
Read The Data From S3 To Local Pyspark Dataframe.
Web feb 1, 2021 the objective of this article is to build an understanding of basic read and write operations on amazon. Read the text file from s3. To read json file from amazon s3 and create a dataframe, you can use either. Now, we can use the spark.read.text () function to read our text file:
Note That Our.json File Is A.
Now that we understand the benefits of. Interface used to load a dataframe from external storage. Interface used to load a dataframe from external storage. Pyspark supports various file formats such as csv, json,.
Web If You Need To Read Your Files In S3 Bucket You Need Only Do Few Steps:
Web step 1 first, we need to make sure the hadoop aws package is available when we load spark: Web spark sql provides spark.read.csv (path) to read a csv file from amazon s3, local file system, hdfs, and many other data. Web this code snippet provides an example of reading parquet files located in s3 buckets on aws (amazon web services). Web and that’s it, we’re done!
We Can Finally Load In Our Data From S3 Into A Spark Dataframe, As Below.
Web read csv from s3 as spark dataframe using pyspark (spark 2.4) ask question asked 3 years, 10 months ago. It’s time to get our.json data! Web spark read json file from amazon s3. Web to read data on s3 to a local pyspark dataframe using temporary security credentials, you need to: